FPVT--Face Pyramid Vision Transformer
3 Information Technology University, Pakistan 4 Electronics and Telecommunications Research Institute, South Korea
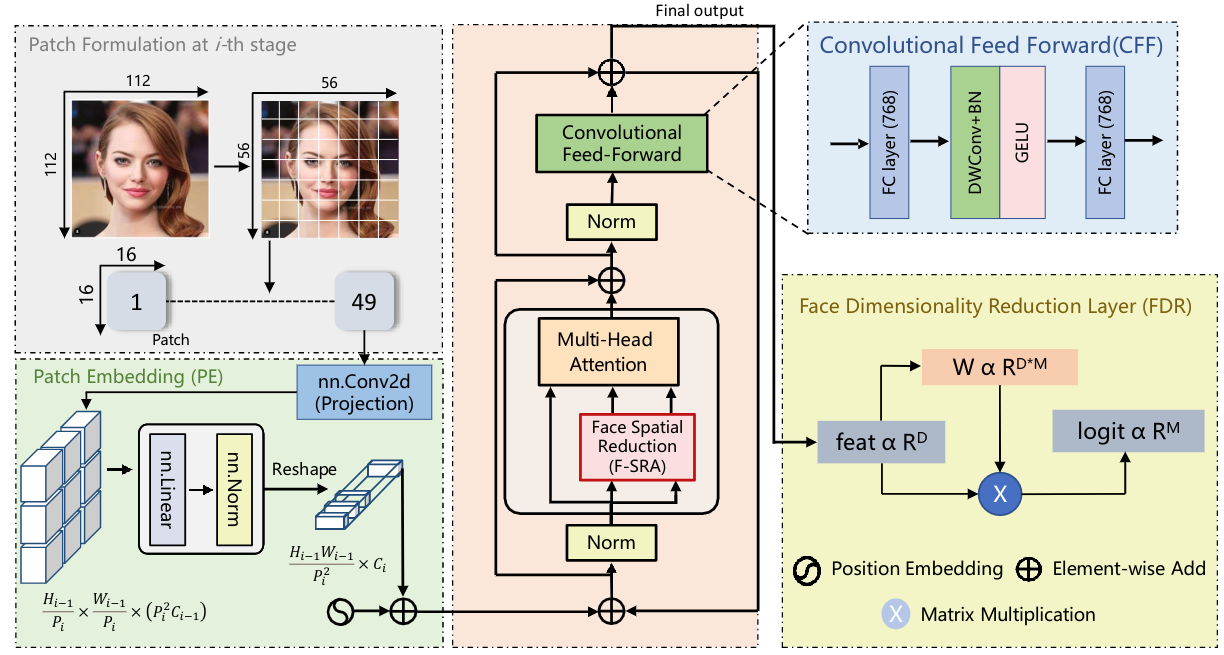
A simplified view of Face Pyramid Vision Transformer (FPVT) with limited computational resources. The whole network represents a pyramid structure, every stage comprises of an improved patch embedding layer and encoder layer.Following progressive shrinking strategy, the output resolution is diverse at every stage from high to low resolution.
News
- 6/10/2022: We will release the extended version of our FPVT paper soon.
Highlights
- FPVT introduces a CFFN that extracts locality information
- We present Face Pyramid Vision Transformer (FPVT) to learn multi-scale discriminative
- We introduce IPE which utilizes all benefits of CNNs to model low-level edges to higher-level semantic primitives
Abstract
A novel Face Pyramid Vision Transformer (FPVT) is proposed to learn a discriminative multi-scale facial representations for face recognition and verification. In FPVT, Face Spatial Reduction Attention (FSRA) and Dimensionality Reduction (FDR) layers are employed to reduce the computations by compacting the feature maps. An Improved Patch Embedding (IPE) algorithm is proposed to exploit the benefits of CNNs in ViTs (e.g., shared weights, local context, and receptive fields) to model low-level edges to higher-level semantic primitives. Within FPVT framework, a Convolutional Feed- Forward Network (CFFN) is proposed that extracts locality information to learn low level facial information. The proposed FPVT is evaluated on seven benchmark datasets and compared with ten existing state-of-the-art methods including CNNs, pure ViTs and Convolutional ViTs. Despite fewer parameters, FPVT has demonstrated excellent performance over the compared methods.
Evaluation & Results
We conduct multiple ablation studies to validate the impact of our proposed work in our FPVT modules. Table. 1 and Table 2 present the results of CNNs, pure ViTs, and Convolutional ViTs on seven datasets. PVT (referred to as baseline) is a standard pure pyramid transformer without convolution. We choose PVT as a baseline due to two main reasons i) it generates multi-scale features ii) the number of parameters is larger than ResNet18. The introduction of the IPE block leads to a gain of 1% in terms of performance, highlighting the impact of convolutional tokens. IPE block improves the performance on LFW from 78.8% to 82.9%, CFP_FF from 75.2% to 85.5%, CFP_FP from 52.9% to 65.6%, AgeDB from 59.9% to 65.6%, CALFW from 66.8% to 70.1%, and CPLFW from 55.1% to 59%.
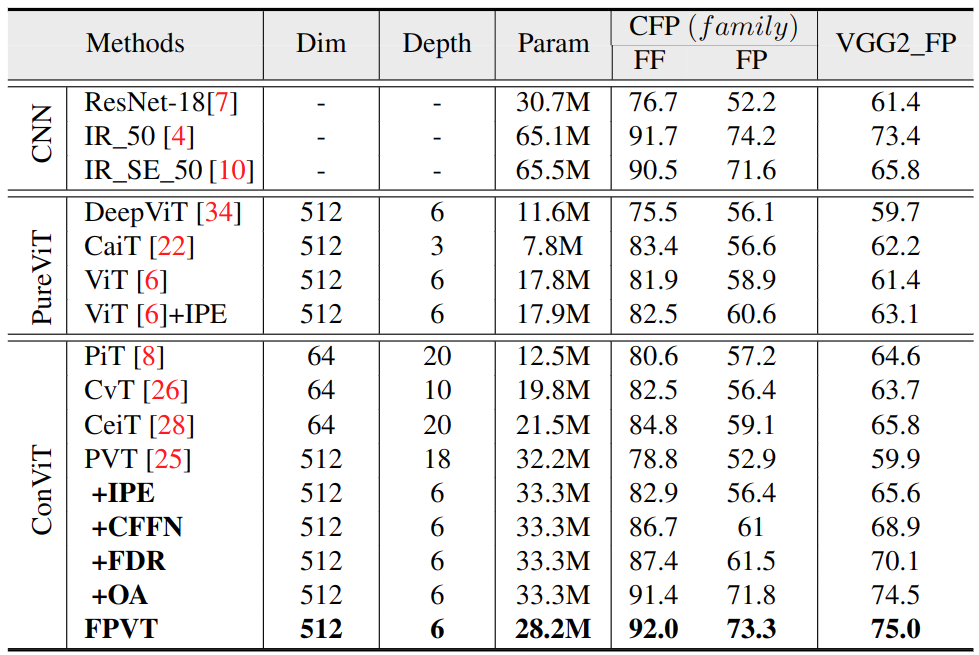
Table 1: Evaluation results on CFP_FF, CFP_FP and VGG2_FP. The top first three models lists the results of the CNN models, while the mid-block presents the performance of pure ViTs architectures. The third block shows the results of Conv. ViTs models.
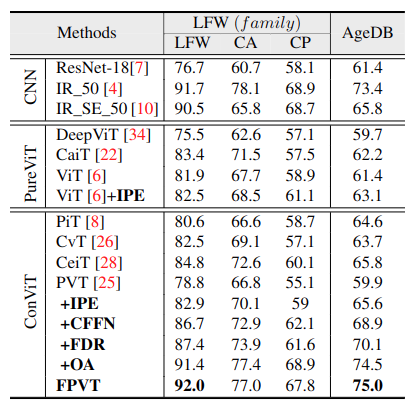
Table 2: Evaluation results on LFW, CALFW, CPLFW and AgeDB: Comparison with FPVT, CNNs, PureViTs and Convolutional ViTs methods. The top first three models represents the results of most representative CNN models, while the mid block indicates the performance of pure ViTs architectures. The third block shows the results of Conv. ViTs models
Citation
@InProceedings{Khawar_BMVC22_FPVT,
author = {Khawar Islam, Muhammad Zaigham Zaheer, Arif Mahmood},
title = {Face Pyramid Vision Transformer},
booktitle = {Proceedings of the British Machine Vision Conference},
year = {2022}
}
@inproceedings{islam2021face,
title={Face Recognition Using Shallow Age-Invariant Data},
author={Islam, Khawar and Lee, Sujin and Han, Dongil and Moon, Hyeonjoon},
booktitle={2021 36th International Conference on Image and Vision Computing New Zealand (IVCNZ)},
pages={1--6},
year={2021},
organization={IEEE}
}
Contact
If you have any question, please contact to Khawar Islam at khawarr dot islam at gmail dot com.